Data Ingest Monitoring for Amazon S3
TL;DR: You can now use Lariat to monitor the data integrity of S3 objects. Lariat will find data issues with objects as soon as they are written to a user-specified bucket and prefix. Reach out to us if you’re interested!
Ensuring data integrity of S3 Objects is about more than just ensuring valid checksums or successful object creation. The file needs to be inspected to ensure that columns have values consistent with expectations, that data isn't missing, and that downstream processing is halted as soon as an issue is found. With our latest product, all it takes is a 5 minute install to get this deeper understanding of the quality of data in object storage.
Object storage like s3 is an increasingly popular first destination for raw data ingest. The advent of formats like Parquet, Iceberg & Delta Lake allows analytical tools to query data directly off s3 and easily separate compute and storage at low cost. As a result, object storage is also becoming the de-facto underlying storage layer for business data in Data Lakes and Lakehouses. This means that monitoring data on object storage is increasingly important and can play a huge role in both catching data integrity/quality issues and preventing needless downstream processing and incorrect analytics.
Why did we build this?
Our customers use us to monitor their datasets and receive alerts for things like “Do I have missing data in North Carolina because of bad data from a supplier?” or “Has there been a sudden decrease in the number of IOS users because of an issue with my transform job?”. To do this, we either track data-at-rest sources like Athena and Snowflake or data in-motion sources like data returned by Python APIs.
In order to fix issues raised by Lariat, we found that our customers would often trace the issue all the way to problems with raw data ingestion onto object storage like S3. Four main problems kept cropping up for our customers:
Teams have difficulty sifting through a large number of file-ingest events (anywhere from 1000 to 100,000/day) to figure out which ones had issues
Managing several sources of data like paid partners or external services is taxing to data engineering teams
When data is partially written, context about failed processing can slip away when not actively tracked
Poorly formatted files can be written because not all formats on object storage enforce schema
We decided to extend our platform to allow users to proactively monitor object storage and reduce mean time to resolve critical data issues before any wasteful downstream processing on bad data.
Our Solution
When a file is added to a monitored S3 bucket and prefix, the Lariat monitoring agent will:
Check for the existence of chosen columns
Track summary statistics on these columns broken out by dimensions
Monitor success or failure of the task consuming the object
Display a timeline of events that have caused an object to change
As seen below, the platform summarizes s3 events and allows you to filter by a variety of dimensions like time, object_prefix and status. You can also see a timeline of s3 events that caused an object to change.

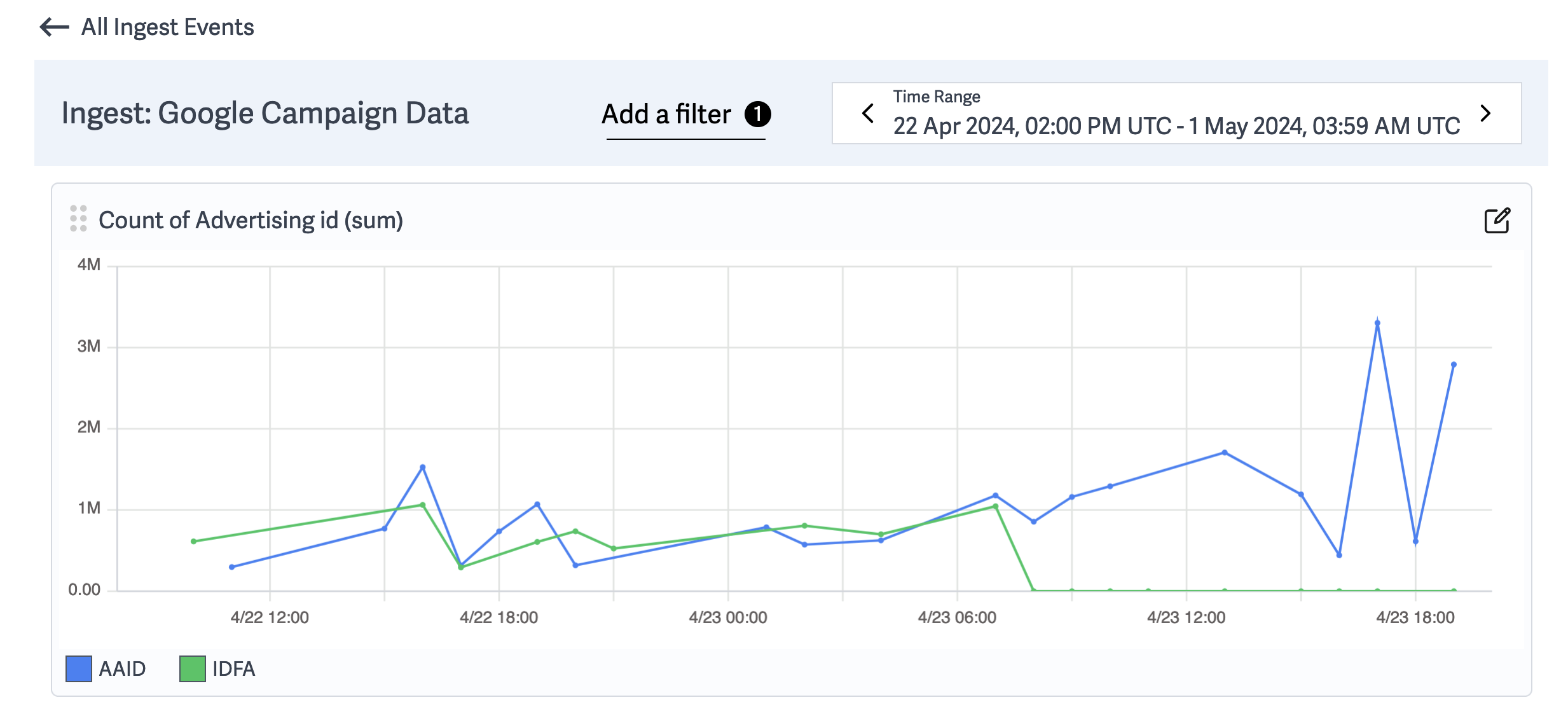
From the warning message on the screenshot, we see that the latest file ingested into our bucket for Google Campaign Data has triggered a warning related to the lower counts than expected for the IDFA advertising ID type. With this information, we can:
dig deeper into object-level metrics via the “View Dashboard” action to create a more detailed bug report
flag this with the data provider and notify of a possible SLA breach
if necessary, copy the json s3 event representing the ObjectCreated:Copy and re-push to SQS/SNS
Clicking into the “View Dashboard” button leads to pre-built dashboards that showcase object-level metrics. Below, we group on our pre-configured dimension “advertising ID” to get a better understanding of the reduced number of rows with value IDFA . We can also expand our filter to check if this issue is isolated to just this object or if it impacts all google campaign data starting from 4/23 at 8:00.
Now that we know when the problem began and which objects it impacted - we can rapidly debug and re-ingest the data.
Much like our other integrations, we focused on making installation as easy as possible. Our one-line installation takes ~3 mins to run and will start monitoring the objects referenced in the configuration file (docs can be found here). The installer is open-source and can be found here.
The code for the S3 monitoring agent is also open-source and can be found here with the relevant README.
We currently support Parquet, CSV, and JSON data with plans to support more.
Our Data Ingest Monitoring product for S3 is now in open beta. If you’re interested in a free trial, sign up below and we will be in touch within 24 hours.


